PLAYBOOK · CAPITAL MARKETS
A real-time trading desk copilot — inside the bank perimeter.
Traders read more than they trade. Research notes, internal positions, news feeds, and risk dashboards arrive faster than humans can correlate them. This playbook builds a low-latency multi-agent network that surfaces high-confidence signals and explains them — entirely on-prem.
Trading is a latency game. Most AI tools targeting capital markets either run in a cloud the bank cannot use or take seconds to respond — both fatal. VDF AI runs entirely inside the bank perimeter and routes per latency budget. Specialist agents read positions, macro feeds, research notes, and risk dashboards; the synthesizer emits a single explained signal.
The problem
Signals exist; correlation doesn't
The fixed-income desk has positions data here, macro research there, sell-side notes elsewhere. By the time a trader synthesizes them, the move is half-priced.
The VDF AI approach
Specialist agents, low-latency network
A Positions Agent, a Macro Agent, a News Agent, and a Risk Agent feed a Signal Synthesizer. The Network runs continuously inside the bank perimeter — no market or position data leaves.
WHY THIS MATTERS NOW
Real-time AI on the desk demands real on-prem
Capital-markets workflows have constraints other industries do not: positions data cannot leave, latency budgets are unforgiving, and explainability is now a compliance requirement under MAR and equivalent regimes.
VDF AI was designed to fit that constraint set. Local model hosting, sub-second routing through SEEMR, and a structured "signal + drivers + conflicts" output format that traders and surveillance both accept. The Network sits beside your OMS — never in front of it.
WHAT YOU NEED TO START
Prerequisites for a pilot
Data feeds
- Market data terminal or feed
- Internal positions read API
- News feed (internal or licensed)
- Research notes archive
Infrastructure
- On-prem GPU node
- Low-latency message bus
- Optional: co-located inference
- Strict retention policies
People
- One head of desk
- One e-trading engineer
- One quant or strategist
- Optional: surveillance / compliance liaison
REFERENCE ARCHITECTURE
From data feeds to explained signal
SEEMR · low-latency tier
PLAYBOOK · STEP BY STEP
From feeds to desk-ready intelligence
Wrap market data and position systems
Each becomes a typed Custom HTTP tool. Authentication and rate limits live in AgentsHub.
Vectorize research and notes
VDF Data indexes sell-side notes, internal research, and prior trade post-mortems with strict retention policies.
Build the specialist agents
Each operates on a tight system prompt with a fixed output schema (signal, confidence, drivers, conflicts).
Compose the Network with a latency budget
SEEMR routes the synthesizer to your fastest private model; specialist agents run smaller models in parallel.
Explain every recommendation
Traders see drivers, conflicts, and confidence with citations to the source feeds. Live Execution Monitoring keeps a full audit trail.
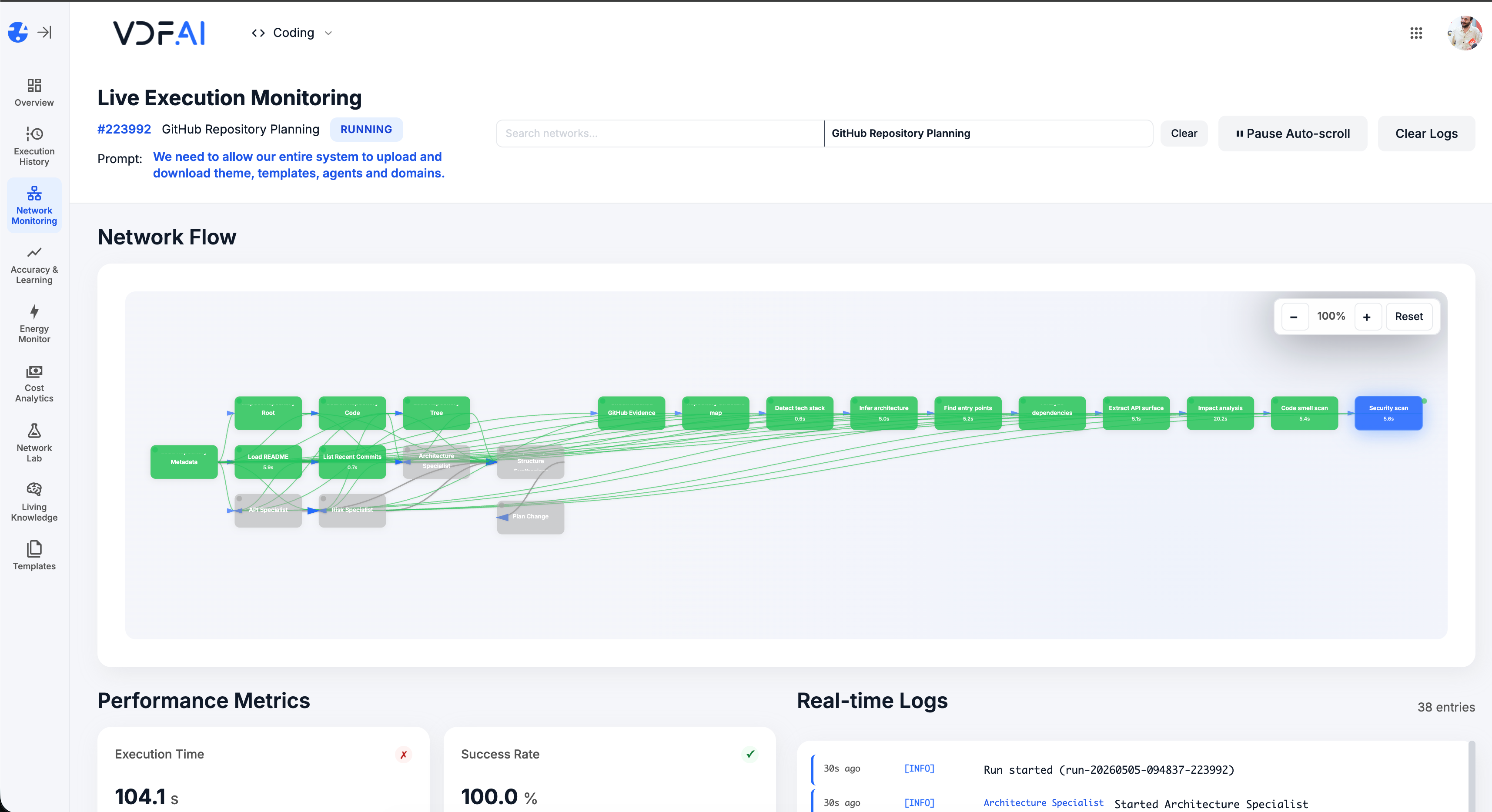
OUTCOMES
Traders see signal, not noise
median signal-to-screen latency on a single GPU node.
signals carry drivers, conflicts, and source citations.
positions or market data leaves your perimeter.
SEEMR REFERENCE
Routing tuned for latency budgets
Trading is a latency game. SEEMR protects the latency budget by routing each sub-intent to the fastest model that meets quality.
FREQUENTLY ASKED QUESTIONS
What teams ask before shipping this playbook
Does this auto-trade?
No. The Network surfaces explained signals to a human trader. Auto-execution is out of scope.
How is MAR / market abuse compliance handled?
Every signal carries its drivers and source citations. Surveillance teams can replay the run from end to end.
What is the latency floor?
Sub-second on a single GPU node for routine signal synthesis. Higher latency only for complex sub-intents routed to larger models.
Can it ingest sell-side notes?
Yes, via the Private RAG. Notes are vectorized with full provenance and indexed per asset class.
Does this work for fixed income, FX, equities, and crypto?
Yes — each desk uses its own Network with asset-class-specific agents.
How long to pilot?
Eight weeks: data integration, agent authoring, latency tuning, and shadow-mode validation.
RELATED PLAYBOOKS
Continue with related VDF AI patterns


GET IN TOUCH
You Have Questions
Tell us what you’re trying to achieve—governed AI Networks, enterprise RAG, deep integrations, or on‑premise deployment. We’ll help you map the right architecture, security posture, and rollout path. If you’re moving beyond AI pilots and need scalable, auditable execution, reach out—our team is ready to help.