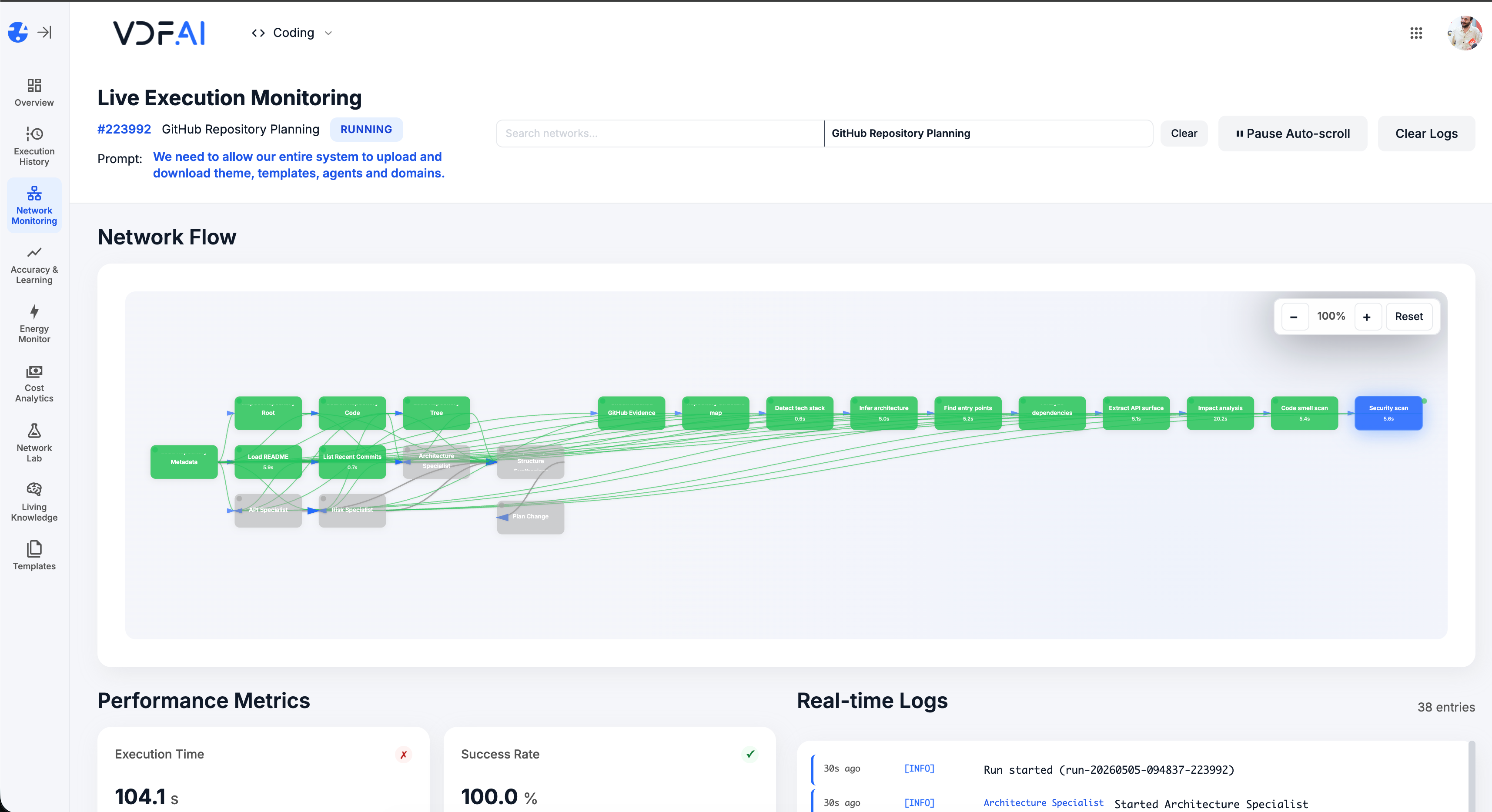
PLAYBOOK · MODELS
Fine-tune a private small language model from your own data.
Public models are general-purpose; your work isn't. This playbook uses VDF Data to extract examples from your live sources, generate fine-tune datasets, train an on-prem SLM, and route to it via SEEMR — without your training data ever leaving the network.
Fine-tuning is usually pitched as an ML problem. In practice it is an integration problem: extracting the right examples, formatting them, splitting train and eval, getting the dataset past privacy review, and finally training a model. VDF Data covers the full pipeline. Then SEEMR routes to your fine-tuned model only when it actually wins.
The problem
Fine-tuning is an integration project, not an ML one
Most teams know what to fine-tune but stall on the dataset: extracting examples, formatting JSONL, splitting train/eval, and getting all of it past privacy review.
The VDF AI approach
A pipeline from source to served model
VDF Data extracts examples from databases, tickets, and chats; generates fine-tune datasets in the format your trainer needs; and serves the trained SLM behind the same Networks v3 surface as any other model.
WHY THIS MATTERS NOW
Fine-tuning pays off only with the right pipeline
The most common reason fine-tuning fails to deliver is not the model — it is the data. Examples are stale, formats are inconsistent, eval splits are leaky, and there is no production routing strategy. Months of work end up shelved.
VDF Data fixes the data side. Versioned Feature Lists define reproducible subsets. Fine-tune datasets are exported in OpenAI JSONL, Anthropic format, or generic CSV with row-level provenance. Once the trained model is registered, SEEMR handles the production routing — promoting the model only on sub-intents where it actually outperforms.
WHAT YOU NEED TO START
Prerequisites for a pilot
Data
- Source systems with task-relevant examples
- Schemas and field-level definitions
- Eval gold set (out-of-distribution)
- Optional: prior labelled examples
Compute
- GPU cluster or managed fine-tune endpoint
- Storage for checkpoints and artifacts
- Network access to model registry
- Hyperparameter strategy
People
- One data engineer
- One ML engineer
- One product owner for the target task
- Optional: a privacy reviewer
REFERENCE ARCHITECTURE
From source data to routed SLM
Tickets · Chats · Docs · DB
Versioned subsets
OpenAI / Anthropic / CSV
Your GPU cluster
PLAYBOOK · STEP BY STEP
From raw data to served fine-tuned model
Define the training feature list
In VDF Data, select the columns, fields, or document types that define the task. Versioned feature lists keep training and evaluation reproducible.
Generate the fine-tune dataset
Export in OpenAI JSONL, Anthropic format, or generic CSV. Provenance is attached to every row.
Train on-prem
Hand the dataset to your GPU cluster or a managed fine-tune endpoint inside your perimeter. VDF AI's Model Evaluation Suite compares the result against the base model.
Register the trained SLM
Add it to the VDF AI model registry with tags, energy/cost profile, and rate limits.
Route through SEEMR
Use SEEMR rules to send the right sub-intents to your fine-tuned SLM and watch the cost and energy curve bend.
OUTCOMES
Your model, your data, your stack
training data leaves your perimeter.
cost per call when SEEMR routes routine sub-intents to the private SLM.
feature lists make every training run auditable.
SEEMR REFERENCE
The fine-tuned model joins a learning fleet
Your SLM doesn't operate alone. SEEMR watches its outcomes against cloud and base models — promoting it for the sub-intents it wins and protecting against regressions.
FREQUENTLY ASKED QUESTIONS
What teams ask before shipping this playbook
When should we fine-tune vs. just RAG?
Start with RAG. Fine-tune when retrieval alone cannot close the gap on a specific, repeated sub-task — typically format adherence, classification, or stylistic consistency.
Which model families work?
Any model your trainer supports. Common targets are Llama family, Mistral family, Phi, Qwen, and proprietary models with fine-tune APIs.
How is the eval split protected?
Feature Lists are versioned and immutable. The eval split is locked at creation and cannot drift.
Do we need to hold out PII?
Yes — VDF Data supports field-level masking and synthetic replacement during dataset export.
How is the trained model registered?
Add it to the model registry with tags, capability profile, and cost/energy metadata. SEEMR uses those for routing.
How long does a fine-tune cycle take?
Two to four weeks: dataset construction, training, eval, registration, and SEEMR ramp-up.
RELATED PLAYBOOKS
Continue with related VDF AI patterns


GET IN TOUCH
You Have Questions
Tell us what you’re trying to achieve—governed AI Networks, enterprise RAG, deep integrations, or on‑premise deployment. We’ll help you map the right architecture, security posture, and rollout path. If you’re moving beyond AI pilots and need scalable, auditable execution, reach out—our team is ready to help.